http://markezine.jp/article/detail/19321
的確なターゲティングには、どのようなデータが必要なのでしょうか。今回は、ターゲティングに用いるデータの生成から、ディスプレイ広告での利用までわかりやすく解説します。
ターゲティングとデータについて考える
前回は、ターゲティングの仕組みについてディスプレイ広告の表示を例に解説したが、今回はその知識を踏まえてさらに理解を深めたいと思う。
ターゲティングの仕組みを理解するうえで外せないのが、ターゲティングに用いられるデータである。ターゲティングの手法は利用するデータによって区分できると言ってもよい。今回はターゲティングに利用されるデータの種類、データの生成方法について解説したい。
ディスプレイ広告で利用可能なデータとは
インターネットには膨大な量のデータが存在し、その種類も多岐にわたる。たとえば、いま閲覧しているウェブページも、ページにアクセスするに際に利用するIPアドレスもその一部である。ディスプレイ広告では、それらのデータを何らかの方法で取得し、分類することでターゲティングを実現している。
インターネット上で取得できるデータの中でも、ディスプレイ広告のターゲティングに利用されるデータは、主に「サイトデータ」「ユーザーデータ」「行動データ」の3種類ある。まず、それぞれの特徴について説明しよう。

サイトデータ
インターネット利用者が閲覧するウェブサイトに掲載されているコンテンツのデータである。画像や文章などコンテンツの内容によって分類される。たとえば、アメリカで話題の野球選手を特集しているウェブページであれば、「海外」「スポーツ」のような内容に関連するカテゴリが割り振られる。

ユーザーデータ
インターネット利用者についてのデータを指す。しかし、名前、住所、電話番号などの個人情報ではないことに注意したい。
ターゲティングを行うとき、インターネットにアクセスする際に使われているウェブブラウザを1人のインターネット利用者と見立てている。たとえば、同じブラウザから何度もアクセスがあったとき、同じインターネット利用者からアクセスがあったと見なされる。ブラウザが特定できれば個人を特定する必要はないのである。ブラウザの特定には、主に後述するCookieを用いる。

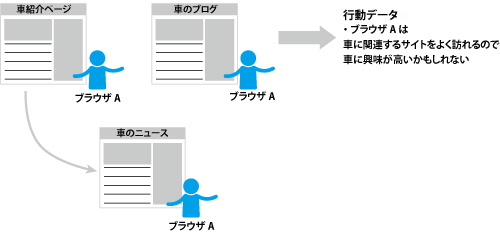
行動データ
インターネットにアクセスしているウェブブラウザごとのウェブサイト閲覧履歴のデータである。見方を変えれば
行動データ=サイトデータ×ユーザーデータ
と表現することもできる。ただし、ユーザーデータと同様、個人情報を取得しないよう配慮する。行動データは主に閲覧したサイトのURLやクリックした広告などに限られる。
サイトデータとユーザーデータを掛け合わせることで、どのブラウザがどんなサイトを訪れる傾向があるか分析でき、分析対象のブラウザを利用しているインターネット利用者の特性を推測することが可能となる。たとえば、頻繁に車に関連するウェブサイトを閲覧していれば、車に関しての興味が高いと推測できる。
データの種類とターゲティングの関係性
前回紹介した5つのターゲティング手法は、それぞれのどのようなデータを利用しているのだろうか。それをまとめたのが以下の表である。
| ターゲティングの種類 | 利用目的 | データの種類 |
|---|---|---|
| サイトターゲティング | サイトを指定することで、広告表示先 ウェブサイトを閲覧している消費者に 広告を表示する。 | サイトデータ |
| コンテンツ ターゲティング | ウェブページのコンテンツに関連する 広告を表示することで、訴求内容に 興味を示すであろう人に広告を表示 する。 | ユーザーデータ |
| デモグラフィック ターゲティング | 訴求内容に興味を示す可能性の高い 属性情報を持つネット利用者に広告 を表示する。 | ユーザーデータ |
| 行動ターゲティング | 訴求内容に興味・関心がある人に 広告を表示する。 | 行動データ |
| リターゲティング | 自社サイトを訪れた人が、外部サイト を閲覧しているときに広告を表示して 再来訪を促す。 | 行動データ |
それでは、これら3種類のデータはそれぞれどのように生成されるのだろうか。その生成方法の一部を紹介しよう。
「サイトデータ」の生成方法
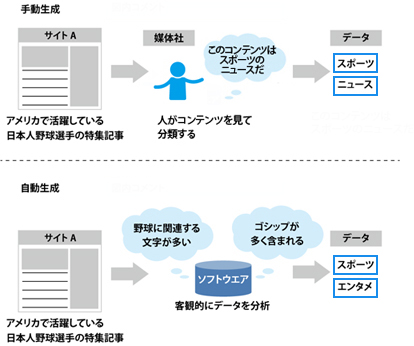
サイトデータの生成方法は、“手動”と“自動”の2種類に分類できる。
手動でサイトデータを生成する場合、サイトを運営する媒体社自身がサイトデータを定義するのが一般的と言える。この場合、媒体社はコンテンツに関連するカテゴリを自ら選ぶことができる。しかし反面、人が手動でカテゴリを割り振るため、間違いが発生したり、ページ数が多い場合にはサイト単位でカテゴリが括られるケースもある。
対して、自動でサイトデータを生成する場合、まずクローリング等の技術を用いてウェブページごとのコンテンツ情報を収集する。そして収集したコンテンツ情報に対して自然言語処理を行うことで、ウェブページごとに細かくサイトデータを割り振ることができる。機械的に行うことで、大量のウェブページを客観的にカテゴライズできることが大きなメリットだ。筆者が所属するマイクロアドでは、機械的な手法でウェブサイトデータの判断を行うことを好む。
「ユーザーデータ」の生成方法
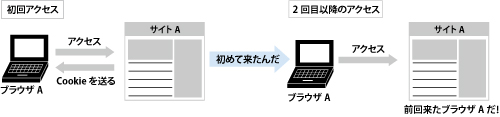
ターゲティングの際に、1ブラウザを1ユーザーと見立てるときに主に利用されるのは「Cookie」である。Cookieとは、インターネット利用者がブラウザを通じてウェブページを閲覧したときに、ウェブサイト側が(正確にはドメインごとに)設定値を一時的に保存できる"箱"のような仕組みだ。
例を挙げると、旅行予約サイトで以前検索した旅行の目的地が再訪問時にも表示されるなど、都度同じ情報を入力したり、設定する手間を省くためにCookieは利用される。広告配信事業者も同じ技術を活用して、ターゲティングを行う。マイクロアドの場合は、ユニークなIDをブラウザごとに発行し、記録することで1ブラウザを1ユーザーと識別できるようになる。
では、Cookieを利用して1ブラウザーを1ユーザーを見立てたあとは、どのようにしてユーザーデータを生成するのだろうか?
ユーザーデータはそもそも「テクノグラフィック」と呼ばれるIPアドレス、利用ブラウザ、ブラウザの言語設定など、ユーザーが利用しているブラウザのインター ネットアクセス環境から取得できるデータと、「デモグラフィック」と呼ばれるユーザーの年齢、性別、所得、職業などの人口統計学的な属性情報の2種類に分類できる。
マイクロアドではこれらのデータを、Cookieを通してブラウザに保存したユーザーを識別するためのIDに紐付けるかたちでターゲティングを行っている。 ここではデモグラフィックなユーザーデータの生成方法に焦点を当ててみたいと 思う。
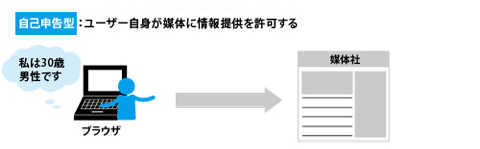
(1)自己申告型
デモグラフィックなユーザーデータの生成方法のひとつ目は、インターネット利用者に許諾を得たうえでデータを提供してもらう「自己申告型」である。この場合においても、性別・年齢・職業といった属性情報はあくまでもCookieと紐づくだけであり、個人を特定しないよう配慮する。しかし、実際には自身の属性情報を提供するインターネット利用者は少ない。
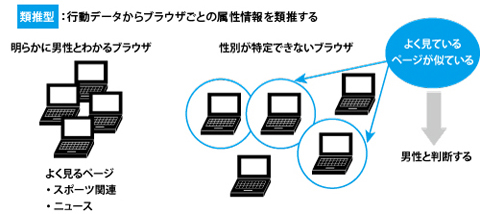
(2)類推型
2つ目のパターンは、行動データを利用することでブラウザごとの属性を類推する「類推型」である。ユーザー数が多い媒体社はユーザーに許諾を得るかたちでデモグラフィックなデータを利用することが比較的行いやすい。自社運営のサイトを持たないマイクロアドの場合は、主にインターネット利用者の行動データから属性情報を類推することで、デモグラフィックなデータを利用したターゲティングを提供している。
「行動データ」の生成方法
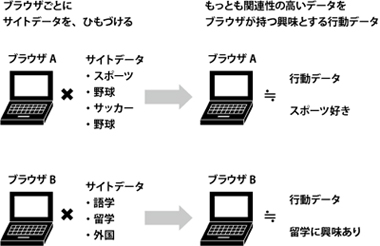
行動データはさきほども説明したとおり、サイトデータとユーザーデータの掛け合わせで生成される。行動データの生成においても、個人情報ではなくCookieを利用する。
行動データの生成は、ブラウザことに関連するサイトデータを明確化することにあると言ってもよい。特定のブラウザに紐づくサイトデータを分類すると、どのカテゴリのコンテンツをよく閲覧しているかが明らかになる。そこから、そのブラウザを利用している人は当該カテゴリに興味を示していると考えることができる。
マーケティングとプライバシー
ここで注意したいのは、あくまでもマーケティングに利用できる性別・年齢や大まかなアクセス地域などを広告配信に利用することで、インターネット利用者のプライバシー侵害を避ける配慮を行なっている点だ。「個人情報」と「ブラウザのCookie情報」と「属性情報」を切り分けることで、プライバシーの侵害を防ぐようにしなければならない。また、行動履歴を取得されたくないユーザーに対しては「オプトアウト」の手段を提供することも事業者は配慮する必要がある。
広告配信事業者向けのガイドラインとして、日本ではJIAA(インターネット広告推進協議会)が提示する「行動ターゲティング広告ガイドライン」、米国ではIABが提示する"Self-Regulatory Principles For Online Behavioral Advertising"などがある。一度、目を通しておくことをおすすめする。
まとめ
今回はターゲティング広告で主に利用されるサイトデータ・ユーザーデータ・行動データの詳細と生成方法について解説した。次回以降は、ターゲティング広告を実現するうえで重要となるデータ量とデータの質について触れたいと思う。

0 件のコメント:
コメントを投稿